TP2 : Approximation with neural networks#
Goal for the day: Building a playground for testing the approximation properties of neural networks.
Warmup:#
Go to https://playground.tensorflow.org/
and train a neural net to 0 training loss on the four type of data.
import torch
import torch.optim as optim
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
1. Define our network#
Question: Write two fully connected networks, with dims \(1, h, 1\) and \(1, h, h, h, h, 1\), respectively
class MLPshallow(nn.Module):
def __init__(self, hidden_dim=10):
super().__init__()
self.net_type = 'shallow' # for keeping info
self.hidden_dim = hidden_dim
# YOUR CODE HERE
def forward(self, x):
x = F.relu(self.l1(x))
x = self.lout(x)
return x
class MLPdeep(nn.Module):
def __init__(self, hidden_dim=10):
super().__init__()
self.net_type = 'deep' # for keeping info
self.hidden_dim = hidden_dim
# YOUR CODE HERE
def forward(self, x):
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
x = self.lout(x)
return x
class MLPshallow(nn.Module):
def __init__(self, hidden_dim=10):
super().__init__()
self.hidden_dim = hidden_dim
self.net_type = 'shallow' # for keeping info
self.l1 = nn.Linear(1, self.hidden_dim)
self.lout = nn.Linear(self.hidden_dim, 1)
def forward(self, x):
x = F.relu(self.l1(x))
x = self.lout(x)
return x
class MLPdeep(nn.Module):
def __init__(self, hidden_dim=10):
super().__init__()
self.hidden_dim = hidden_dim
self.net_type = 'deep' # for keeping info
self.l1 = nn.Linear(1, self.hidden_dim)
self.l2 = nn.Linear(self.hidden_dim, self.hidden_dim)
self.l3 = nn.Linear(self.hidden_dim, self.hidden_dim)
self.l4 = nn.Linear(self.hidden_dim, self.hidden_dim)
self.l5 = nn.Linear(self.hidden_dim, self.hidden_dim)
self.lout = nn.Linear(self.hidden_dim, 1)
def forward(self, x):
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
x = F.relu(self.l5(x))
x = self.lout(x)
return x
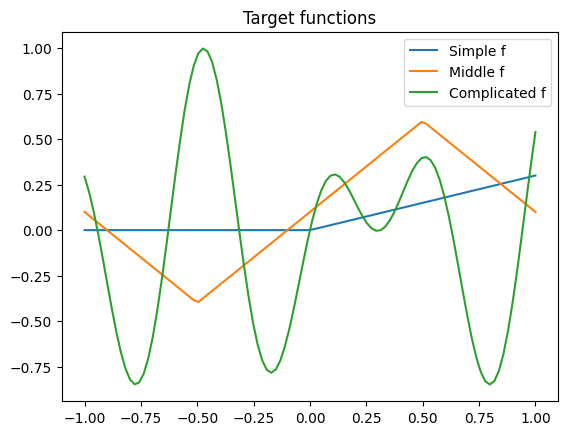
Objective: Train a neural net to approximate some arbitrary functions#
Here we define the function we are going to try to approximate.
def simple_f(x):
return np.maximum(.3*x, 0)
def middle_f(x):
return np.abs(x+.5) - 2 * np.maximum(x-.5, 0) - .4
def complex_f(x):
return np.sin(10 * x) * np.cos(2 * x + 1)
xs = np.linspace(-1, 1, 100)
plt.plot(xs, [simple_f(x) for x in xs], label='Simple f')
plt.plot(xs, [middle_f(x) for x in xs], label='Middle f')
plt.plot(xs, [complex_f(x) for x in xs], label='Complicated f')
plt.title('Target functions')
plt.legend()
plt.show()
class Data():
'''
Generates batches of (labels, responses) pairs, of the form (x_i, f(x_i) + noise).
x_i are 1-dimensional
'''
def __init__(self, n=1000, xmin=-1, xmax=1, noise_level=1e-2, type='simple'):
self.n = n # number of data points
self.xmin = xmin # min feature
self.xmax = xmax # max feature
self.noise_level = noise_level # gaussian noise of variance noise_level**2
self.type = type # define the target function
self.inputs = torch.empty(n, 1) # all inputs in our dataset
self.outputs = torch.empty(n, 1) # all responses
self.fill_data() # fill inputs and outputs
self.pass_order = np.arange(n) # will be shuffled every time we go through the data
self.current_position = 0 # current position in pass order. Used to generate batches.
def true_f(self, x):
if self.type == 'simple':
return simple_f(x)
if self.type == 'middle':
return middle_f(x)
if self.type == 'complex':
return complex_f(x)
def next_batch(self, batch_size=10):
pos = self.current_position
self.current_position = (self.current_position + batch_size) % self.n
indices = self.pass_order[pos: pos+batch_size]
input_batch = torch.stack([self.inputs[i] for i in indices])
output_batch = torch.stack([self.outputs[i] for i in indices])
if pos + batch_size > self.n:
np.random.shuffle(self.pass_order)
return input_batch, output_batch
def fill_data(self):
for i in range(self.n):
x = self.xmin + np.random.rand() * (self.xmax - self.xmin)
y = self.true_f(x)
self.inputs[i] = x
self.outputs[i] = y + self.noise_level * np.random.normal() * (np.random.rand() < .15)
def __len__(self):
return self.n
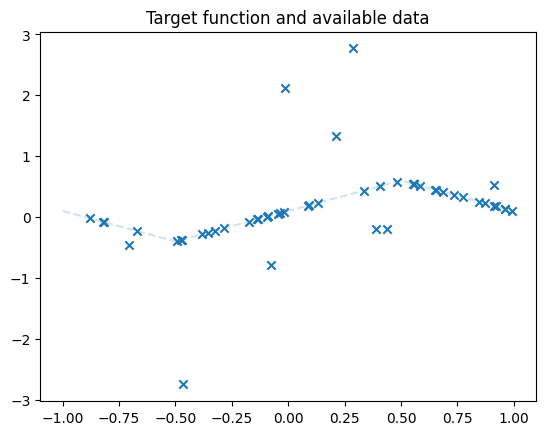
dataset = Data(50, type='middle', noise_level=1)
plt.title('Target function and available data')
plt.plot(xs, dataset.true_f(xs), linestyle='--', alpha=.2, label='True values')
plt.scatter(dataset.inputs, dataset.outputs, marker='x')
plt.show()
4. Train a network#
In this section we train a network to match the target function, given the observed points.
hidden_dim = 100
mlp = MLPdeep(hidden_dim=hidden_dim) # Initialize a network
total_train_steps = 0 # for log keeping
all_losses = [] # for log keeping
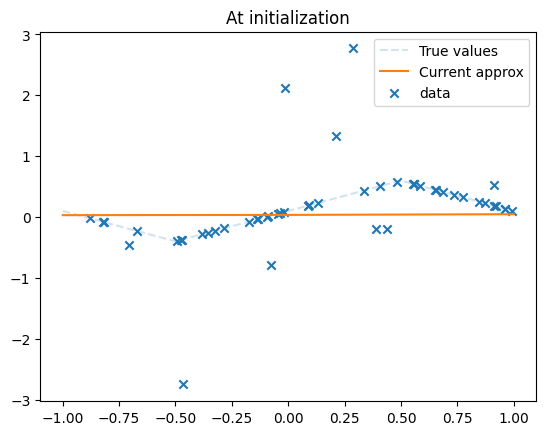
def plot(net, dataset, n_points=1000):
with torch.no_grad():
xs = torch.linspace(-1, 1, n_points).reshape(n_points, 1)
nn_values = net(xs)
true_vals = dataset.true_f(xs)
plt.plot(xs, true_vals, linestyle='--', alpha=.2, label='True values')
plt.plot(xs, nn_values, label='Current approx')
plt.scatter(dataset.inputs, dataset.outputs, marker='x', label='data')
print(f'Squared error of O pred: {np.linalg.norm(true_vals)**2 / n_points}')
print(f'Squared error of mlp: {np.linalg.norm(nn_values - true_vals)**2 / n_points}')
print(f'total_train_steps : {total_train_steps}')
plt.legend()
plot(mlp, dataset)
plt.title('At initialization')
Squared error of O pred: 0.0932499235305304
Squared error of mlp: 0.08509111325140929
total_train_steps : 0
Text(0.5, 1.0, 'At initialization')
Training#
We are going to try to compute an approximate least-squares neural network, by minimizing $\( \frac{1}{n} \sum_{ \text{data}} (h_w(x_i) - y_i)^2 \)\( To do so, we use the standard neural net training procedure: (stochastic) gradient descent on then weights of the neural network. \)\( w_{t+1} = w_t - \mathrm{lr} \cdot \nabla_w f(w_t; (x_i, y_i)) \)\( where \)\( f(w; (x_i, y_i) ) = \frac{1}{n} \sum_{ \text{data}} (h_w(x_i) - y_i)^2 \, . \)$
Defining the optimizer and loss#
You can come back and tune the learning rate if necessary.
optimizer = optim.SGD(mlp.parameters(), lr=0.001)
criterion = nn.MSELoss()
Write the training procedure. Go to TP1 if you need a reminder on the syntax.
N_steps = 100000
batch_size = 30
losses = []
for i in range(N_steps):
inputs, labels= dataset.next_batch(batch_size)
#print(inputs.shape)
optimizer.zero_grad()
# forward + backward + optimize
outputs = mlp(inputs)
loss = criterion(outputs, labels)
loss.backward()
losses.append(loss.detach().numpy())
optimizer.step()
total_train_steps += batch_size
all_losses += losses
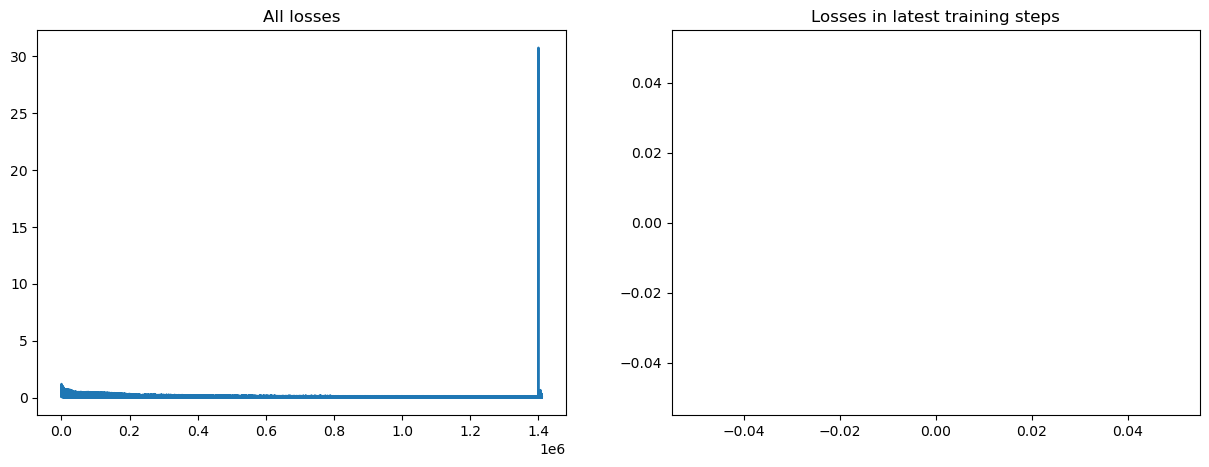
fig, axs = plt.subplots(1, 2, figsize=(15, 5))
print(f'Total training steps : {total_train_steps}')
axs[0].set_title('All losses')
axs[0].plot(all_losses)
axs[1].set_title('Losses in latest training steps')
axs[1].plot(losses)
plt.show()
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[11], line 9
7 inputs, labels= dataset.next_batch(batch_size)
8 #print(inputs.shape)
----> 9 optimizer.zero_grad()
11 # forward + backward + optimize
12 outputs = mlp(inputs)
File ~/anaconda3/envs/py39/lib/python3.9/site-packages/torch/_compile.py:24, in _disable_dynamo.<locals>.inner(*args, **kwargs)
20 @functools.wraps(fn)
21 def inner(*args, **kwargs):
22 import torch._dynamo
---> 24 return torch._dynamo.disable(fn, recursive)(*args, **kwargs)
File ~/anaconda3/envs/py39/lib/python3.9/site-packages/torch/_dynamo/decorators.py:46, in disable(fn, recursive)
44 fn = innermost_fn(fn)
45 assert callable(fn)
---> 46 return DisableContext()(fn)
47 return DisableContext()
48 else:
File ~/anaconda3/envs/py39/lib/python3.9/site-packages/torch/_dynamo/eval_frame.py:437, in _TorchDynamoContext.__call__(self, fn)
434 assert callable(fn)
436 try:
--> 437 filename = inspect.getsourcefile(fn)
438 except TypeError:
439 filename = None
File ~/anaconda3/envs/py39/lib/python3.9/inspect.py:706, in getsourcefile(object)
703 elif any(filename.endswith(s) for s in
704 importlib.machinery.EXTENSION_SUFFIXES):
705 return None
--> 706 if os.path.exists(filename):
707 return filename
708 # only return a non-existent filename if the module has a PEP 302 loader
File ~/anaconda3/envs/py39/lib/python3.9/genericpath.py:19, in exists(path)
17 """Test whether a path exists. Returns False for broken symbolic links"""
18 try:
---> 19 os.stat(path)
20 except (OSError, ValueError):
21 return False
KeyboardInterrupt:
N_steps = 1000
batch_size = 10
losses = []
for i in range(N_steps):
# YOUR CODE HERE
# do not forget to fill 'losses' for tracking the train loss
total_train_steps += batch_size
all_losses += losses
fig, axs = plt.subplots(1, 2, figsize=(15, 5))
print(f'Total training steps : {total_train_steps}')
axs[0].set_title('All losses')
axs[0].plot(all_losses)
axs[1].set_title('Losses in latest training steps')
axs[1].plot(losses)
plt.show()
Total training steps : 28210000
plot(mlp, dataset)
plt.title('After training')
Squared error of O pred: 0.0932499235305304
Squared error of mlp: 0.0924277368953708
total_train_steps : 30000
Text(0.5, 1.0, 'After training')
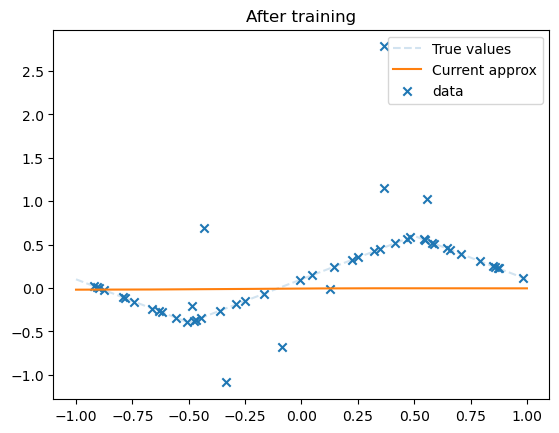
Train your network until the plot looks good.
5 - Compare the performances on different functions for different depths.#
Plot the approximation after \(N \approx 1\,000\,000\) steps for the two architectures (with, e.g., hidden_dim = 15) on the three functions.
def train(net, dataset, N_steps, batch_size, lr):
optimizer = optim.SGD(net.parameters(), lr=lr)
criterion = nn.MSELoss()
for _ in range(N_steps):
inputs, labels= dataset.next_batch(batch_size)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
n_points = 10000
all_data_types = ['simple', 'middle', 'complex']
all_net_types = ['shallow', 'deep']
N_steps = 100_000
batch_size = 10
lr = 0.01
fig, axs = plt.subplots(2, 3, figsize = (20, 10))
for i, type in enumerate(all_data_types):
dataset = Data(30, type=type)
net_shallow = MLPshallow(hidden_dim=20)
train(net_shallow, dataset, N_steps, batch_size, lr)
xs = torch.linspace(-1, 1, n_points).reshape(n_points, 1)
nn_values = net_shallow(xs).detach().numpy()
true_vals = dataset.true_f(xs)
axs[0, i].plot(xs, true_vals, linestyle='--', alpha=.2, label='True values')
axs[0, i].plot(xs, nn_values, label='Current approx')
axs[0, i].scatter(dataset.inputs, dataset.outputs, marker='x', label='data')
net_deep = MLPdeep(hidden_dim=20)
train(net_deep, dataset, N_steps, batch_size, lr)
xs = torch.linspace(-1, 1, n_points).reshape(n_points, 1)
nn_values = net_deep(xs).detach().numpy()
true_vals = dataset.true_f(xs)
axs[1, i].plot(xs, true_vals, linestyle='--', alpha=.2, label='True values')
axs[1, i].plot(xs, nn_values, label='Current approx')
axs[1, i].scatter(dataset.inputs, dataset.outputs, marker='x', label='data')
This is not good practice to train networks. For performance, the hyperparameters for each problem and architecture should be tuned separately and you should monitor the state of the network (at least plot the losses during training).
You can use the following code snippet to save your network.
# mlp = MLPdeep() # MLPshallow()
# PATH = f'./{dataset.type}_{mlp.net_type}.pth'
# torch.save(mlp.state_dict(), PATH)
# net = MLPdeep() # MLPshallow()
# net.load_state_dict(torch.load(PATH))